DBMS의 버퍼 관리
질의 과정에서 데이터에 접근하기 위해서는 테이블의 레코드들이 실제 물리 메모리의 버퍼 공간에 할당되어야 한다. 물리 메모리는 디스크에 비해 매우 적은 공간이며 이에 따라 적절한 교체 정책이 필요하다. DBMS는 <Frame Number, page ID>로 이를 관리한다. 이는 메모리 버퍼의 몇 번 프레임에 디스크의 몇 번 페이지를 올렸는지를 의미한다.
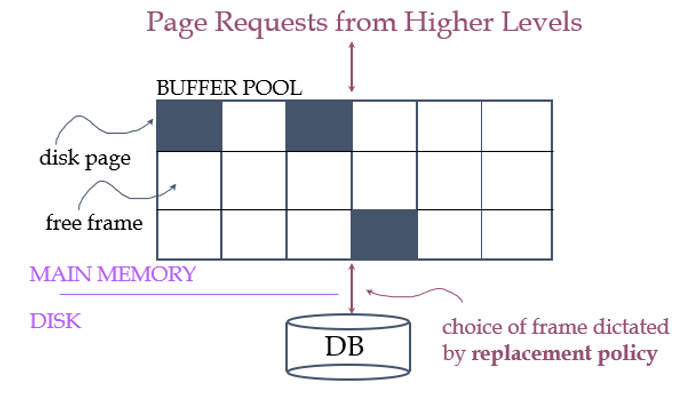
특정 페이지가 요청된 경우의 시나리오는 다음과 같다.
IF) 해당 페이지가 버퍼에 존재할 경우 -> 바로 반환
ELSE) 해당 페이지가 버퍼에 존재하지 않는 경우
- 버퍼에서 교체할 프레임을 선택한다.
- 교체할 프레임이 dirty면 이를 디스크에 기록한다.
- 요청한 페이지를 디스크에서 버퍼의 해당 프레임으로 로드한다.
각 프레임은 pin count로 얼마나 사용되고 있는 지를 기록하여 교체할 프레임 선정에 고려한다. dirty bit는 프레임의 내용이 변경되었을 경우 이를 실제 디스크에 반영해야 함을 의미한다.
쿼리 비용 추정
DBMS에서는 사용자의 질의를 적절한 관계 대수 트리 형태로 표현한다. 이 때 어떤 연산을 사용해야 이를 효율적으로 처리할 지 내부적으로 평가하게 된다. 이 평가에는 Catalog가 이용된다. Catalog는 데이블과 인덱스에 관한 통계적인 정보를 의미한다. Catalog에는 각 테이블 별 튜플과 페이지의 수, 인덱스 별 고유한 키 값과 페이지의 수, 인덱스 별 높이와 최대/최소 키 값 등의 정보가 존재한다.
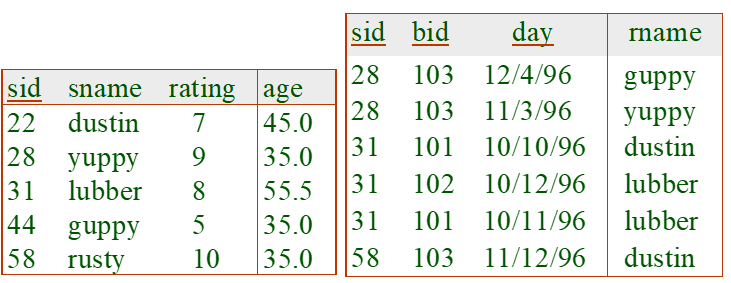
가정
Sailors 테이블: 튜플 당 50Bytes, 한 페이지에 80개의 튜플이 존재하며, 총 500개의 페이지 존재
Reserves 테이블: 튜플 당 40Bytes, 한 페이지에 100개의 튜플이 존재하며, 총 1000개의 페이지 존재
Selection 연산의 페이지 IO 추정
SELECT * FROM Reserves
WHERE rname<'C%'<rname> 인덱스가 존재할 경우, 이름이 'C%'보다 작은 경우는 'A%', 'B%'로 약 10프로라고 가정할 수 있다. 이때 클러스터 여부에 따라 추정되는 비용은 다음과 같다.
- 클러스터: 1,000/10 = 100 IO
- 넌클러스터: 1,000*100/10 = 10,000 IO
클러스터의 경우 정렬되어 있어 유사한 값은 전부 근처에 존재하고, 넌클러스터의 경우 그런거 없이 전체 데이터 레코드 중 10퍼센트에 대해 각각 개별적인 페이지 접근이 필요하다.
Projection 연산의 페이지 IO 추정
SELECT R.sid, R.bid FROM Reserves
단순히 반환되는 결과에서 특정 필드만 추출하므로 추가적인 비용이 없으나 DISTINCT가 사용될 경우 정렬/해싱을 통해 중복을 제거하는 작업이 필요하다.
Join 연산의 종류에 따른 비용 추정
추정에 필요한 용어 정리
- M: 외부 릴레이션의 페이지 수
- N: 내부 릴레이션의 페이지 수
- Px: 릴레이션 x의 페이지 당 튜플 수
대부분의 경우에서 Reserves가 외부 릴레이션 M, Sailors가 내부 릴레이션 N으로 가정한다.
1. Simple Nested Loops Join
외부 릴레이션의 페이지를 모두 읽고 각 페이지 내의 튜플 별로 내부 릴레이션의 조인 조건과 맞는 튜플을 매칭하는 방식이다.
연산 비용: M+Pr*M*N
2. Page-oriented Nested Loops Join
사실 위는 현실 적이지 않다. 페이지 내에 모든 튜플이 존재하므로 각 튜플을 다시 접근할 필요가 없다.
연산 비용: M+M*N
3. Block Nested Loops Join
실제 시스템에서는 1개가 아닌 B개의 버퍼 페이지가 존재하여 외부 릴레이션은 이 버퍼를 활용하여 외부 릴레이션의 페이지를 읽어들여 이를 한 그룹의 블럭으로 치환하여 내부 릴레이션의 튜플과 매칭한다. (Block size = 버퍼 크기 - 2)

연산 비용: M+[M/Block Size]*N
4. Index Nested Loops Join
릴레이션의 조인 조건으로 내부 릴레이션의 인덱스를 사용 가능할 경우 인덱스를 사용하여 적은 비용으로 조인하는 연산 방식이다. 예를 들어, 조인 조건이 '번호'이며 외부의 (번호:3, 이름:홍길동) 튜플과 내부 튜플을 조인하려 시도할 경우 내부 릴레이션의 '번호'에 대해 인덱스가 존재할 경우 인덱스로 접근하는 연산 방식이다.
M+M*Pr*(cost of finding matching inner tuples)
이때, 내부 튜플의 매칭 비용은 (엔트리까지 매칭 튜플을 찾는 비용 + 엔트리에서 레코드까지의 탐색 비용)이다.
이에 따른 비용은 인덱스의 파일 구조에 따라 다르다.
- 해시 인덱스: 1.2 + (1 or N)
- B 트리 인덱스: 2~4 + (1 or N)
(1 or N)은 위에서 언급한 엔트리에서 레코드까지의 탐색 비용을 의미한다. 이는 클러스터 여부에 따라 다르다. 만약, 클러스터일 경우 페이지 단위 접근으로 '1'로 끝나지만, 넌클러스터일 경우 'N'이 필요할 수 있다.
예시 1. 내부 릴레이션 Sailors에 해시 인덱스 <sid>가 설정된 경우
M = 1000, Pr = 100
cost of finding matching inner tuples = 1.2 + 1 (이는 기본키는 클러스터이며 중복이 없음을 고려한 결과이다)
따라서, 총 비용은 1000+1000*100*2.2 = 221,000 IO
예시 2. 내부 릴레이션 Reserves에 해시 인덱스 <sid>가 설정된 경우
M = 500, Ps = 80
cost of finding matching inner tuples = 1.2 + 2.5
Reserves에서 sid는 중복이 존재한다. 총 선원은 80*500=40,000이며 예약된 배는 100*1000=100.000 이므로 한 선원 당 2.5개의 배를 예약할 수 있다. 따라서 각 sid마다 2.5개의 중복이 Reserves 릴레이션에 존재한다고 가정할 수 있다.
따라서, 총 비용은 500+500*80*3.7 = 148,500 IO
5. Sort Merge Join
조인 연산 과정에서 각 릴레이션을 정렬한 뒤 병합하는 방식으로 조인한다. 이는 각 릴레이션이 조인 조건을 중심으로 정렬되어 있을 경우 매우 적은 IO를 보장한다.
연산 비용: (MlogM+NlogN+)M+N
Reduction Cardinality
연산 과정에서 조건절 혹은 조인 연산에 의해 아웃풋 릴레이션의 크기가 줄어들 경우 이를 추정해야 다음 연산에 대한 추정이 가능해진다. 이를 추정하기 위한 방법은 아래와 같다.
Reduction Factor(RF; 축소비율)
- col=value, RF = 1/NKeys(I) //NKeys(I): 유니크한 인덱스 키 값의 수
- col>value, RF = [High(I)-value]/[High(I)-Low(I)]
- col1=col2, RF = 1/MAX(NKeys(I1),NKeys(I2))
조건절에 인덱스가 존재할 경우 단일 릴레이션 쿼리에서의 비용 추정
기본키 인덱스가 설정된 경우 데이터 엔트리 까지의 비용은 아래와 같다.
- B 트리: Height(I)+1
- 해시: 1.2
인덱스가 한개 이상의 조건에 매칭되는 경우의 비용
- 클러스터 : (NPages(I)+NPages(R)) × RF
- 넌클러스터: (NPages(I)+NTuples(R)) × RF
순차적인 파일 스캔인 경우의 비용: NPages(R)
예제. 아래 쿼리문에서 <rating>이 클러스터 혹은 넌클러스터, <sid>가 클러스터 혹은 넌클러스터로 존재할 경우 비용
-- rating은 1~10까지 존재 : NKeys(I)=10
-- NPages(I):50, NPages(R)=500, NTuples(R)=40000
SELECT S.sid FROM Sailors S
WHERE S.rating=8 -- col:value -> RF = 1/NKeys(I)
1. <rating>
- 클러스터 : (NPages(I)+NPages(R)) × RF = (50+500) x 1/10 = 55
- 넌클러스터: (NPages(I)+NTuples(R)) × RF = (50+40000) x 1/10 = 4005
2. <sid> : 매칭 인덱스가 조건절에 없으므로 릴레이션이 축소되지 않음
- 클러스터 : (NPages(I)+NPages(R)) × RF = (50+500) = 550
- 넌클러스터: (NPages(I)+NTuples(R)) × RF = (50+40000) = 40050
위의 경우 보통, 순차적인 파일 스캔이 사용되어 500이 소요
조인 연산이 존재하는 쿼리문의 비용 추정
-- 가정- bid:1~100, rating:1~10
SELECT S.sname
FROM Reserves R, Sailors S
WHERE R.sid=S.sid AND R.bid=100 AND S.rating>5
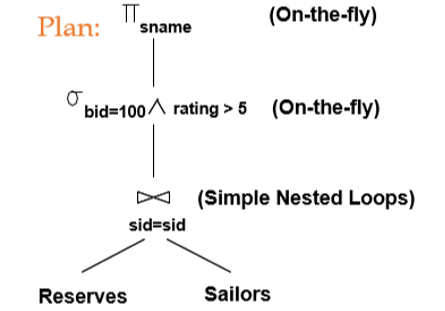
1. Page-oriented Nested Loops Join이 사용되고, 인덱스가 없는 경우
* 연산 비용 : M+M*N
- R이 외부인 경우: 1000+1000*500 = 501,000
- S가 외부인 경우: 500+500*1000 = 500,500
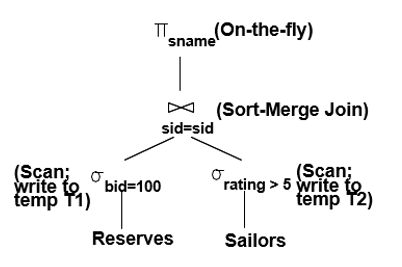
2. Sort Merge Join이 사용되고, 인덱스가 없는 경우
@ push select를 활용 -> join 전에 조건으로 값을 필터링하는 작업
@ 버퍼 크기 = 5
* 연산 추정 과정
① push select 후 임시 테이블 생성
M(=1000)개의 페이지를 읽고 bid=100에 해당하는 1000/100=10개의 페이지를 임시 테이블 T1에 저장
N(=500)개의 페이지를 읽고 rating>5에 해당하는 500/2=250개의 페이지를 임시 테이블 T2에 저장
② 각각의 정렬 비용을 계산하기 위해 pass 수 계산
T1의 pass 수, [log₄10/5] + 1 = 2 => 정렬 비용 : 2*N*pass = 2*10*2 = 40
T1의 pass 수, [log₄250/5] + 1 = 4 => 정렬 비용 : 2*N*pass = 2*250*4 = 2000
③ 병합 비용
M+N = 10+250 = 260
④ 전체 비용
[(1000+10)+(500+250)] + [40+2000+260] = 4060
* Block Nested Loops Join으로 교체할 경우
push select 연산을 통한 ①까지의 과정은 동일하고 ②,③ 이 없어짐 .
① [(1000+10)+(500+250)] + M+[M/BlockSize]*N = 1760+10+4*250=2770
* Push project까지 활용할 경우
Push projection, 연산에 사용될 필드만 남기는 작업
① 의 비용이 바뀜. [(1000+10)+(500+250)] -> [(1000+3)+(500+250)]
위는 Reserves(M)에서 bid 필드만 남기는 작업을 대략적으로 추정한 결과.

3. Reserves에 <bid> 클러스터 해시 인덱스, Sailors에 <sid> 넌클러스터 해시 인덱스가 존재하여 Index Nested Loops Join을 사용하는 경우
* 연산 추정 과정
① R에서 bid=100인 결과만 반환하여 R이 줄어들게 됨
(NPages(I)+NPages(R))*RF = (100+1000)*1/10 = 11
② Index Nested Loops Join 수행
M+M*pr*cost of finding matching inner tuples
= 11+10*100*(1.2+1) = 2211 I/O
내부 릴레이션인 Sailors의 sid는 기본키이므로 중복이 없음
'Domain > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 정규화 (0) | 2021.01.06 |
|---|---|
| [데이터베이스] ISAM과 B+ 트리 (0) | 2021.01.06 |
| [데이터베이스] 9. 인덱스와 인덱스 구조별 비용 추정 (0) | 2021.01.04 |
| [데이터베이스] 8. ESQL(Embedded SQL)와 프로시저(Procedure) (0) | 2020.07.23 |
| [데이터베이스] 7. SQL의 View (0) | 2020.07.23 |



