확률적 경사 하강법
이전 포스팅의 경우 데이터셋이 이미 미리 전부 준비되어있는 상태였다. 하지만, 일부 데이터셋이 준비된 상황에서 시시각각 새로운 데이터셋이 들어오면 이 데이터셋들에 대해서도 훈련을 시켜야한다. 이렇게 원래 학습된 모델을 새 데이터에 대해 업데이트 하는 방식으로 학습하는 모델을 점진적 학습이라고 하고, 그 중 대표적인 알고리즘이 확률적 경사 하강법이다.
확률적 경사 하강법은 훈련 세트에서 랜덤하게 하나의 샘플을 선택하여 가파른 경사를 조금 내려간다. 다음 훈련 세트에서 다시 샘플을 하나 추출하여 경사를 조금 내려가고, 전체 샘플이 소진될 때까지 이를 반복한다. 샘플이 전부 소진되는 한 사이클을 에포크라고 부른다. 그리고 이 에포크 이후에 전체 샘플이 최적점에 도달하지 못했을 경우 계속해서 전부 도달할 때까지 에포크를 반복한다. 조금씩 내려가는 이유는 너무 많이 이동하게 될 경우 해당 최적점을 넘게될 수도 있기 때문이다.
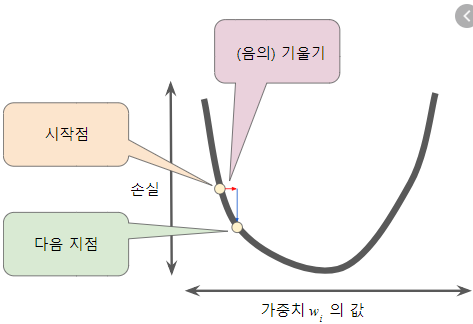
참고로 확률법 경사 하강법은 이전에 학습한 로지스틱회귀/선형회귀와 같은 ML 알고리즘은 아니다. 다만, 이런 ML 알고리즘을 더 최적화 시켜주기 위한 방법이다.
참고로 위에서 한 개씩 사용하는 대신 여러 개의 샘플을 사용하는 방법을 미니매치 경사 하강법이라고 한다. 심지어 극단적으로 전체 샘플을 사용하는 방법도 존재하는데 이를 배치 경사 하강법이라고 부른다.
참고로, 딥러닝에서 확률적 경사 하강법/미니배치 경사 하강법을 자주 사용한다.
손실 함수
손실 함수는 머신러닝 알고리즘이 얼마나 부정확한지를 측정하는 함수이다. 그렇기에 값이 낮을 수록 머신러닝 알고리즘이 좋다고 평가할 수 있다. 손실 함수에서 다루는 경사면은 연속적이어야 한다. 예를 들어, 샘플 4개가 있고 이에 대한 타깃에 대한 가능한 정확도는 0, 1/4, 2/4, 3/4, 1이다. 이렇게 매우 이산적이므로 아주 조금씩 경사 하강법을 이용하여 움직일 수 없다. 수학적으로는 미분 가능하지 않다고 말한다. 즉, 경사 하강법은 미분 가능한 것에만 사용 가능하다. 대표적으로 회귀 모델의 경우 평균 절대값 오차/평균 제곱 오차 수식을 활용하는데 이 식은 미분 가능하여 손실 함수를 사용할 수 있다. 반대로 분류는 이산적이므로 불가능하다.
로지스틱 손실 함수(이진 크로스엔트로피 손실 함수)
로지스틱 손실 함수의 경우 분류 모델에 대해서 머신러닝 알고리즘이 얼마나 부정확한지를 측정할 수 있다. 다음과 같은 이진 분류에서의 예시를 보자.
| 예측 | 타깃 | 손실 |
| 0.9 | 1 | -0.9 |
| 0.3 | 1 | -0.3 |
위의 경우 첫 번째 샘플이 1일 확률은 0.9이다. 1일 확률이 실제 높으므로 손실 함수는 낮아야 한다. 따라서, 예측값과 타깃값을 곱한 뒤 음의 부호를 붙여 손실을 표현한다. 0.3도 비슷하게 진행된다. 0.3은 0.9에 비해 맞힐 확률이 떨어지므로 손실 값이 더 크다.
| 예측 | 타깃 | 손실 |
| 0.2 | 0 | 0.2 -> 0.8 X 1 = -0.8 |
| 0.6 | 0 | 0.6 -> 0.4 X 1 = -0.4 |
반대로 타깃이 0인 경우 둘을 곱하면 0이 되어 측정이 불가능하다. 따라서, 이를 타깃이 0인 음성 클래스 대신 1인 양성 클래스에 대한 예측으로 바꾸어 계산한다. 이렇게 예측 확률을 활용하면 연속적인 손실 함수를 얻을 수 있다. 추가로 로그 함수를 활용하면 더 좋다. 예측 확률의 범위는 0~1 사이이다. 로그 함수는 0~1 사이에서 음수가 되므로 최종 예측 확률(손실) 값은 양수가 되어 측정하기 편하다.

결과적으로는 양성 클래스일 때 손실은 -log(예측확률), 음성 클래스일 때 손실은 -log(1-예측확률)을 사용하여 측정한다.
손실 함수를 직접 계산하는 일은 매우 드물다. 사실 머신러닝 라이브러리가 거의 처리해주고, 왜 정의 해야 하는 지를 이해하는 것이 중요하다.
손실함수를 제공하는 확률적 경사 하강법을 제공하는 분류 클래스 : SGDClassifier
에포크 10회 반복 로지스틱 손실 함수 활용
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv')
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=10, random_state=42) #log: 로지스틱 손실 함수, 반복 10회
sc.fit(train_scaled,train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
훈련 세트: 0.773109243697479
테스트 세트: 0.775
위 결과를 보면 점수가 매우 저조하다. 하지만, 확률적 경사 하강을 통해 추가적인 학습이 가능하다. 이는 partial_fit 메서드를 활용하여 가능하다.
sc.partial_fit(train_scaled,train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
훈련 세트: 0.8151260504201681
테스트 세트: 0.825
에포크와 과대/과소적합
확률적 경사 하강법을 활용하는 모델은 에포크 횟수에 따라 과소/과대적합이 될 수 있다. 에포크 횟수가 적다면 충분히 훈련하지 않아 과소적합되고, 너무 많다면 훈련 세트에만 잘 맞는 모델이 되어 훈련 세트에 과대 적합될 것이다.
결국 적당히 학습하는 것이 중요한데 이를 확인하기 위해 실제 그래프를 그리는 코드는 아래와 같다.
import numpy as np
sc = SGDClassifier(loss='log', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)
for _ in range(0,300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
위 그래프를 보면 100번 에포크 이후 훈련 세트와 테스트 세트의 점수 차이가 조금씩 벌어지는 것을 확인할 수 있다. 그리고, 초반 반복의 경우 과소적합되어 성능이 좋지 않다. 위를 통해 100번의 에포크를 수행하는게 적합하다는 것을 확인할 수 있다.
sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42) #log: 로지스틱 손실 함수, 반복 100회
sc.fit(train_scaled,train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
훈련 세트: 0.957983193277311
테스트 세트: 0.925
'AI: ML,DL' 카테고리의 다른 글
| [인공지능] 심층 신경망 (0) | 2021.03.20 |
|---|---|
| [인공지능] 인공 신경망(딥러닝, DNN) (0) | 2021.03.20 |
| [인공지능] 로지스틱 회귀 (0) | 2021.03.14 |
| [인공지능] 특성 공학과 규제(다중 회귀, 릿지, 라쏘) (0) | 2021.03.13 |
| [인공지능] 회귀: k-최근접 이웃 회귀 (0) | 2021.03.13 |



